들어가며
머신러닝 프로젝트를 시작할 때, 가장 먼저 해야 할 일은 문제를 정의하는 것입니다. "이 고객이 서비스를 떠날 가능성은?", "내일의 주식 시장은 상승할까?", "이 집의 가격은 얼마일까?" 이처럼 머신러닝 문제는 크게 분류(Classification)와 회귀(Regression)로 나눌 수 있습니다. 또한, 데이터를 학습하는 방식에 따라 지도학습(Supervised Learning)과 비지도학습(Unsupervised Learning)으로 구분됩니다. 이번 글에서는 머신러닝의 기본 개념인 지도학습과 비지도학습, 분류와 회귀의 차이, 그리고 머신러닝 모델이 학습하고 평가되는 기본 흐름을 간단히 살펴보겠습니다. 이러한 기초적인 원리를 이해하면, 머신러닝 프로젝트의 전체적인 구조를 파악하고, 실무에서 다양한 문제를 체계적으로 해결할 수 있는 기반을 다질 수 있습니다.
1. 지도학습과 비지도학습: 정답이 있는가, 없는가
지도학습(Supervised Learning): 정답이 있는 학습
지도학습은 입력 데이터(Feature)와 그에 대한 정답(Label)이 있는 데이터를 학습합니다.
모델은 데이터를 통해 입력과 정답 간의 관계를 배우고, 이를 기반으로 새로운 데이터의 결과를 예측합니다.
- 구조:
- 입력(Feature): 예측에 사용되는 데이터. 예: 키, 몸무게, 나이
- 정답(Label): 모델이 학습해야 할 목표 값. 예: BMI, 집값, 암 여부
- 예시:
- "키와 몸무게를 보고 BMI를 예측하라."
- "이 고객이 내 서비스를 떠날지 예측하라."
지도학습은 분류(Classification)와 회귀(Regression) 문제로 나뉩니다. 이에 대한 설명은 아래에서 자세히 다룹니다.
비지도학습(Unsupervised Learning): 정답 없이 학습
비지도학습은 정답(Label)이 없는 데이터를 학습합니다.
모델은 데이터를 분석하여 패턴이나 구조를 스스로 찾아냅니다.
예를 들어, 고객 데이터를 군집화해 특정 그룹의 특징을 알아내는 데 사용됩니다.
- 예시:
- "비슷한 사람들끼리 그룹을 만들어라." (군집화)
- "고객의 구매 패턴에서 숨어 있는 관계를 찾아라." (연관 규칙)

2. 분류와 회귀: 어떤 문제를 해결할까?
분류(Classification): 카테고리를 예측하라
분류는 데이터를 특정 카테고리로 구분하는 작업입니다. 입력 데이터가 어느 그룹에 속하는지 예측하는 것이 핵심입니다.
- 예시:
- "이 이메일은 스팸인가 아닌가?" (스팸/일반 메일)
- "이 고객이 상품을 구매할 가능성은?" (구매/미구매)
- "이 사진은 강아지인가 고양이인가?" (강아지/고양이)
- 분류의 활용
- 의료: 암 진단(양성/음성)
- 금융: 대출 승인(승인/거절)
- 마케팅: 고객 이탈 예측(이탈/유지)
회귀(Regression): 숫자를 예측하라
회귀는 데이터를 바탕으로 연속적인 값을 예측하는 작업입니다.
"몇 점?", "얼마?"와 같은 숫자 예측 문제를 해결합니다.
- 예시:
- "내일의 기온은 몇 도일까?" (20°C, 25°C 등)
- "이 집값은 얼마일까?" (5억 원, 7억 원 등)
- "광고 캠페인이 가져올 매출은?" (10만 원, 50만 원 등)
- 회귀의 활용
- 부동산: 집값 예측
- 기상학: 기온 예측
- 경제: 매출

3. 학습과 평가: 머신러닝 모델의 학습과 평가 흐름
머신러닝에서 지도학습이든 비지도학습이든, 분류 문제든 회귀 문제든, 모델을 학습하고 평가하는 기본적인 흐름은 동일합니다.
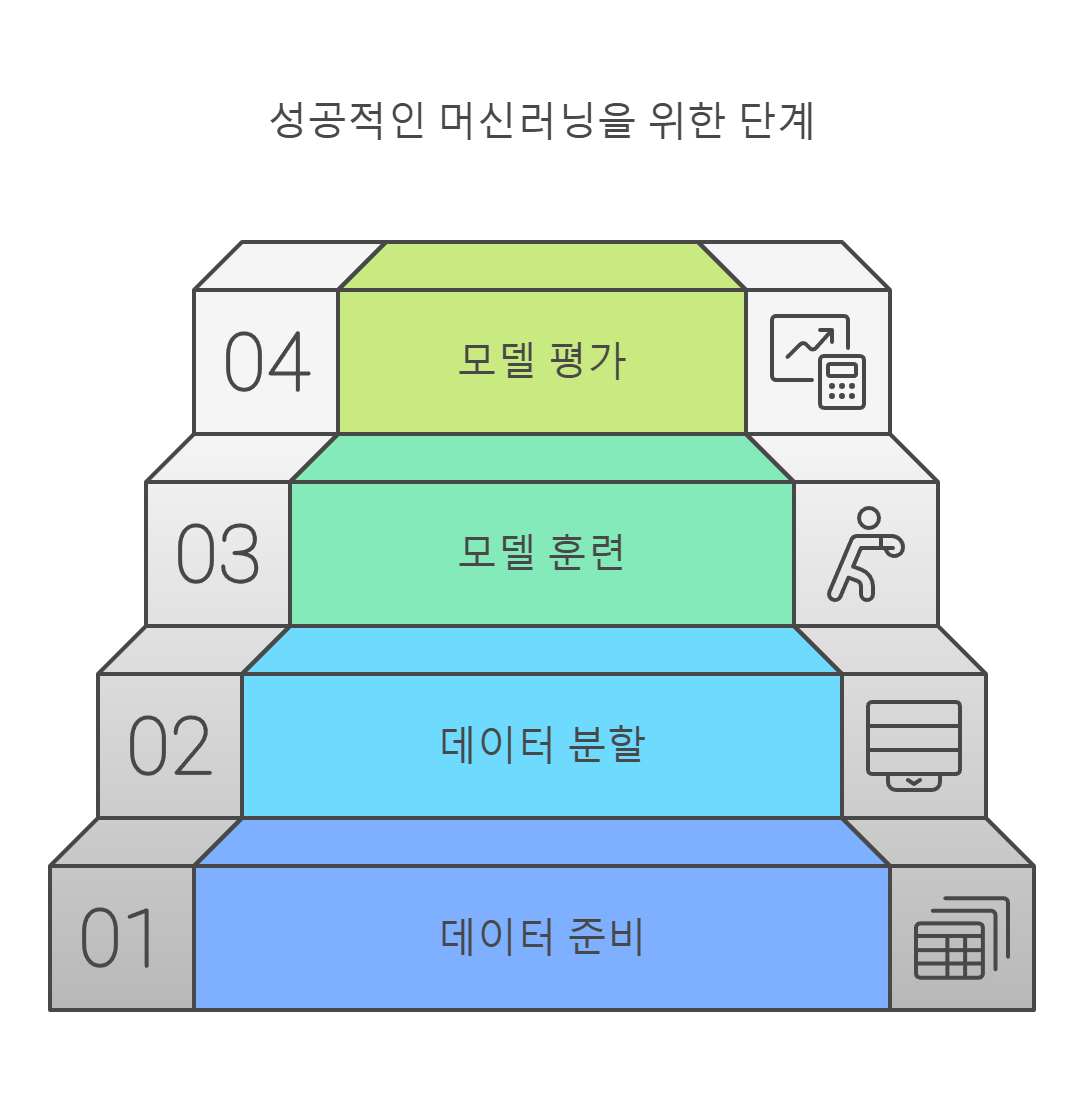
먼저, 데이터 준비 단계에서 데이터를 수집하고 정리합니다. 이후 데이터를 두 부분으로 나눕니다:
- 학습 데이터(Train Data): 모델이 학습하는 데 사용되는 데이터입니다.
- 평가 데이터(Test Data): 모델이 학습하지 않은 새로운 데이터로, 학습된 모델의 성능을 평가하는 데 사용됩니다.
이렇게 준비된 학습 데이터를 사용해 모델이 입력과 출력 간의 관계를 배우게 하고, 이후 평가 데이터를 사용하여 모델이 얼마나 잘 학습되었는지 점검합니다.
이 과정은 문제를 해결하는 모든 머신러닝 프로젝트에서 공통적으로 적용됩니다. 데이터를 나누고, 학습시키고, 평가하는 방식은 문제의 유형이나 데이터의 특성에 관계없이 동일하게 반복됩니다. 이는 머신러닝의 기본 원리이자, 프로젝트를 성공적으로 이끄는 핵심 흐름입니다.
마무리: 머신러닝의 흐름을 이해하며
이번 장에서는 머신러닝의 기본 개념인 지도학습과 비지도학습, 그리고 분류와 회귀에 대해 배웠습니다. 이러한 개념들은 머신러닝 프로젝트를 정의하고 시작하는 데 필수적이며, 앞으로의 내용을 이해하는 데 중요한 토대가 됩니다.
앞으로는 현업에서 직면하는 지도학습 문제 중 다양한 문제를 대표하는 2진 분류(Binary Classification)를 중심으로 내용을 진행할 예정입니다. 다른 유형의 문제나 학습 방식을 다루지 않더라도, 머신러닝 프로젝트의 핵심 흐름은 동일합니다.
데이터 준비 및 학습/평가데이터 분리 → 모델 설계/학습 → 결과 해석/평가
위와 같은 머신러닝 문제 해결의 흐름은 어떤 문제를 풀든 변하지 않습니다. 따라서 이번 ML pipleine 시리즈는 지도학습의 2진 분류를 베이스로 설명하면서도, 이를 통해 머신러닝 프로젝트의 전반적인 과정을 이해할 수 있도록 구성하였습니다. 다음 장부터는 2진 분류 문제를 중심으로 실무에서 실제로 어떻게 머신러닝 프로젝트를 수행하는지 구체적으로 다룰 예정입니다. 이번 시리즈를 통해 여러분이 실무적 흐름을 이해하고, 이를 바탕으로 다양한 문제와 모델에 응용할 수 있는 통찰을 얻어가시길 바랍니다😊.
'Background > ML Pipeline' 카테고리의 다른 글
| 머신러닝의 기초와 분류 문제 해결의 첫걸음 (4) 분류 모델 결과와 앞으로의 방향 (0) | 2024.12.10 |
|---|---|
| 머신러닝의 기초와 분류 문제 해결의 첫걸음 (3) 기초 사용법과 실무적 통찰 (0) | 2024.12.09 |
| 머신러닝의 기초와 분류 문제 해결의 첫걸음 (2) 실습데이터 소개와 머신러닝 엔지니어의 자세 (0) | 2024.12.08 |
| 머신러닝의 기본과 프로젝트 성공의 열쇠 (2) 머신러닝 엔지니어가 꼭 알아야 할 프로젝트의 진짜 모습 (0) | 2024.12.01 |
| 머신러닝의 기본과 프로젝트 성공의 열쇠 (1) 머신러닝 모델이 데이터를 처리하는 방식 (0) | 2024.11.30 |